Managing Offshore QA in 2026: The Quality Operating System
May 19, 2026
- Quality Engineering
- AI in Engineering
- Distributed Teams
- Release Governance

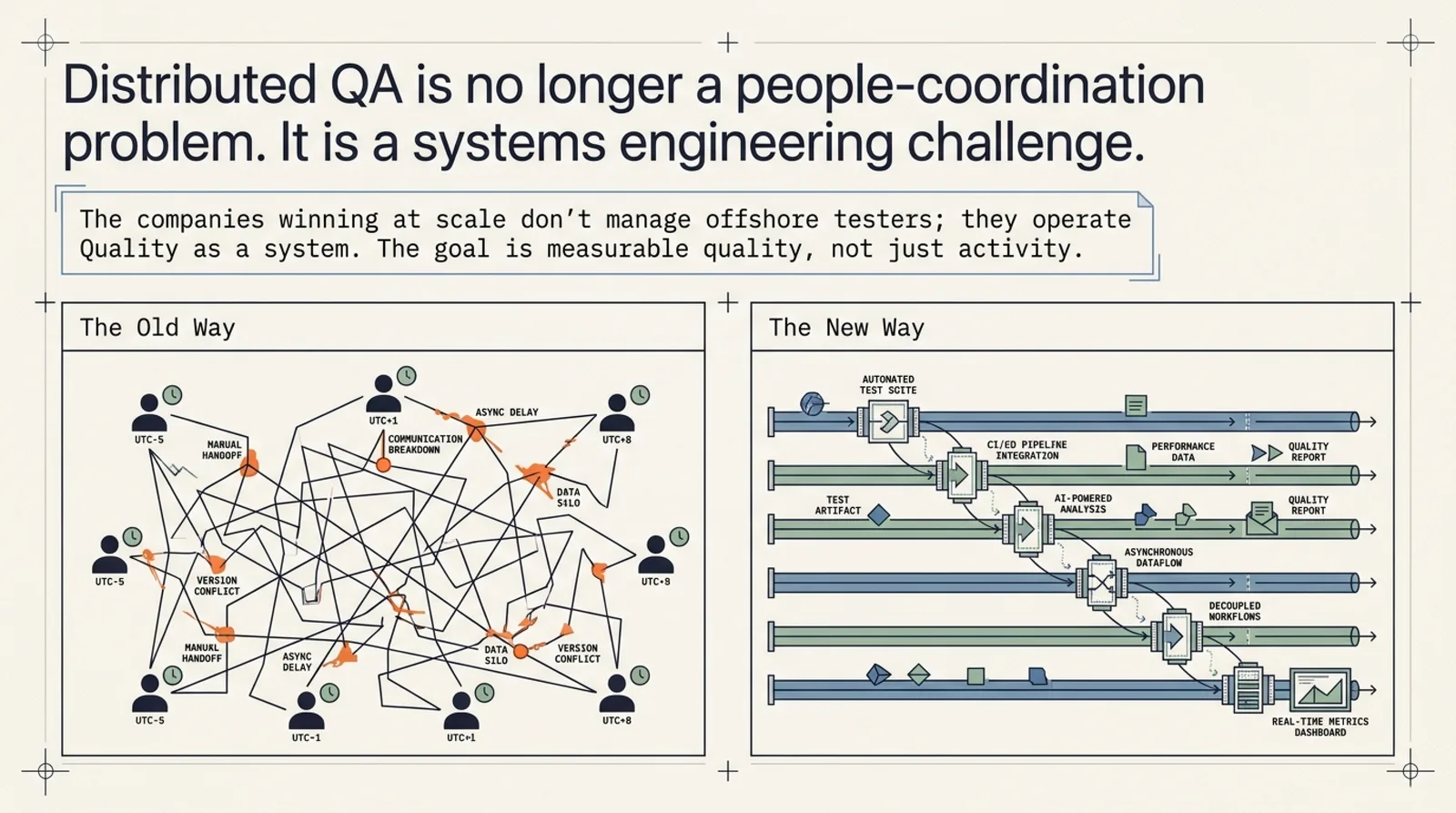
Distributed QA is not a people problem. It is a systems problem.
In most organizations, the same failure mode still repeats itself: manual triage, huge regression suites, fragile staging environments, and release decisions that depend on who is awake in which time zone. That model works when the team is small and co-located. It breaks when delivery becomes distributed.
The teams that scale do not "manage offshore testers." They build a quality system. They use AI to reduce noise, CI to narrow scope, observability to prove impact, and governance to keep the process reliable. The QA leader's job is not to personally approve every release. It is to define how quality decisions get made, what signals count, who owns what, and what evidence is required before a release moves forward.
This is the model I use in practice.
The Quality Operating System
Quality is not a phase at the end of delivery. It is the system teams use to define, execute, verify, and govern software quality.
| Layer | Purpose | What it means in practice |
|---|---|---|
| Definition | Set quality boundaries | Requirements, acceptance criteria, risk areas, and service contracts |
| Execution | Run the right checks | CI pipelines, automation, contract tests, and ephemeral environments |
| Intelligence | Reduce noise and improve decisions | AI-assisted PR analysis, test selection, and failure triage |
| Evidence | Prove quality with signals | Reports, traces, logs, metrics, dashboards, and production correlation |
| Governance | Keep the system stable | Owners, SLAs, release gates, escalation paths, and flaky-test handling |
That is what I mean when I say QA should operate like a system, not a phase.

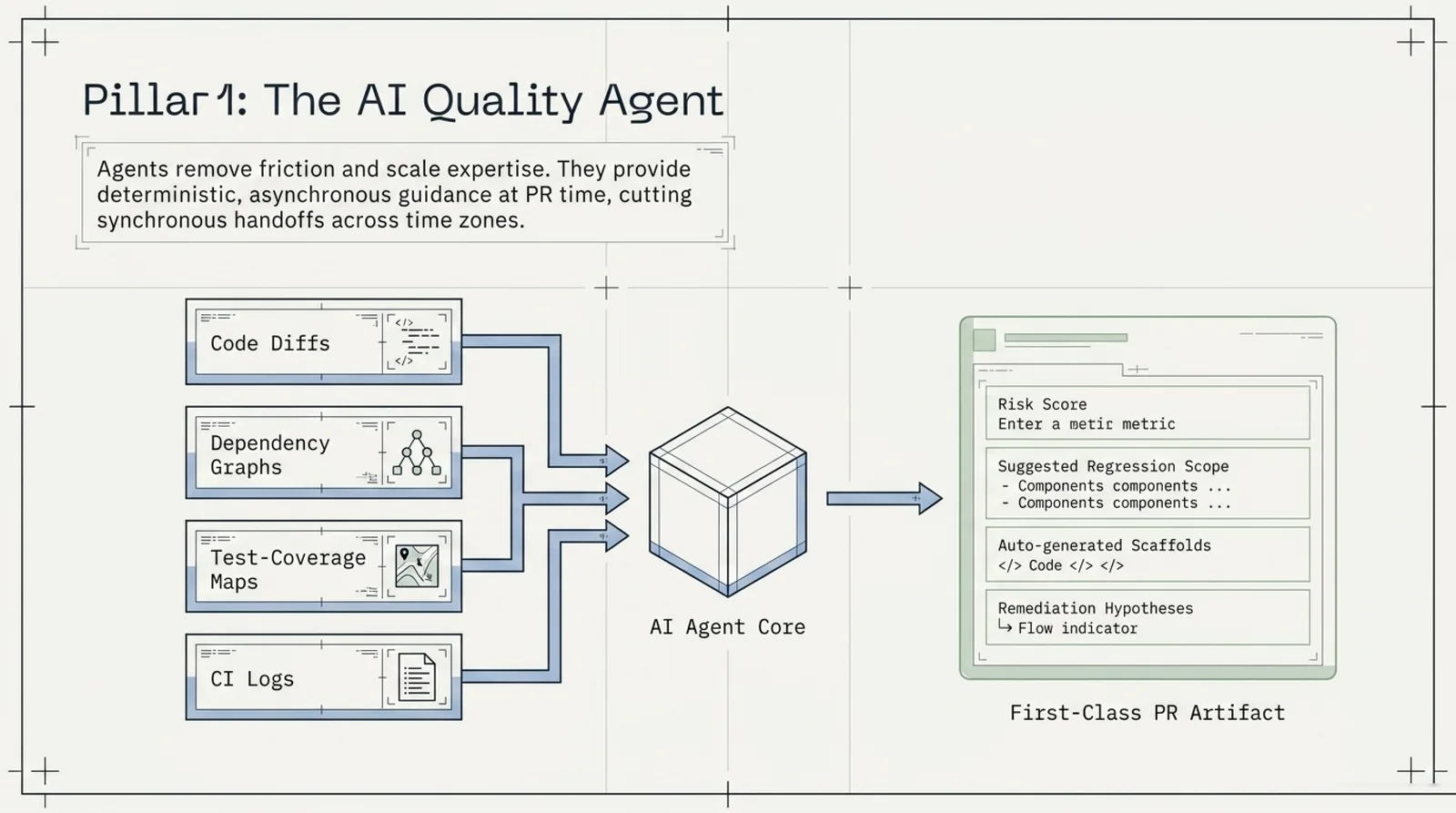
1. AI Quality Agent
Every pull request should produce a risk summary. What changed? What flows are affected? What tests are mandatory? What can wait? What evidence is needed before merge?
That summary does not need to be perfect, but it does need to be fast, repeatable, and useful. In distributed teams, that matters more than manual back-and-forth.
I use AI agents to:
- Read PRs and produce a risk summary with a suggested test scope.
- Generate Playwright or API test skeletons.
- Triage failures by looking at CI logs, recent commits, test history, and flaky-test patterns.
- Flag coverage gaps using coverage maps and dependency graphs.
For UI flows, I prefer browser automation with accessibility snapshots and structured page state. It is more reliable than vision-only exploration and easier to debug when something fails.
Operational rule: every repo should expose a minimal agent contract — how to run locally, how to reach CI logs, and what tests exist. The agent output should become part of the PR conversation, not an extra side channel.
KPI: percentage of PRs with a risk summary; time from PR open to first quality comment.
Real-world outcome: engineers get guidance while they are still in the branch, not after the merge window has already closed.
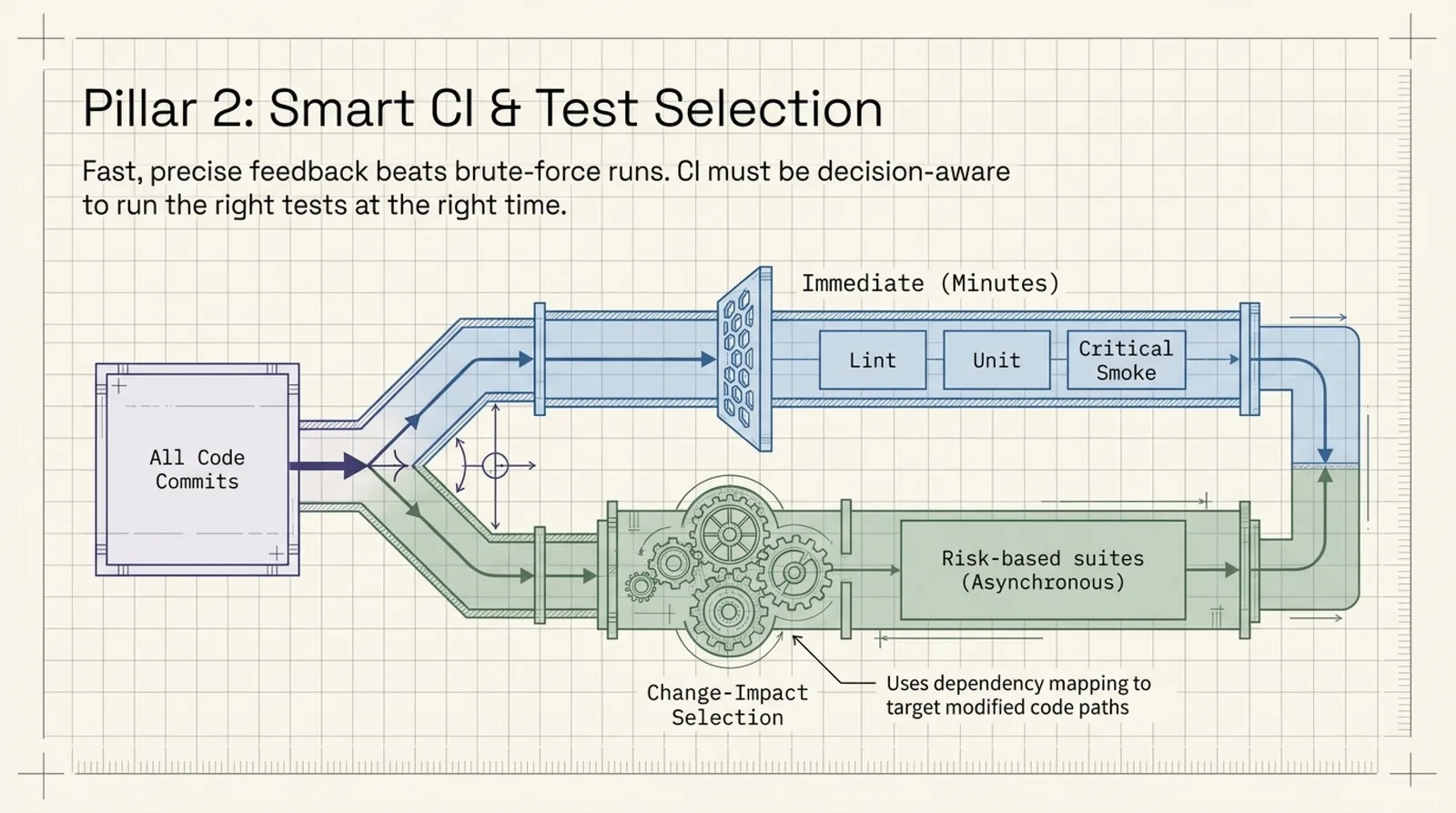
2. Smart CI and Test Selection
Most teams run too many tests too often. The result is slow feedback and very little signal.
Smart CI is not about maximizing coverage in every run. It is about selecting the right tests based on the change, the risk, and the time available.
I use Smart CI to:
- Select tests based on code impact and historical relationships between code and tests.
- Run fast smoke checks first, then targeted integration tests, then broader suites only when needed.
- Reorder or shard jobs when queue time or repeated failures start slowing feedback.
A practical setup usually has two tiers:
- Tier 1: lint, unit, and critical smoke tests, ideally within minutes.
- Tier 2: risk-based suites that run selectively or asynchronously.
KPI: PR feedback time, selected-test accuracy, CI queue time, average job duration.
Real-world outcome: developers stop waiting on irrelevant suites, and offshore engineers stop losing hours to context switching.
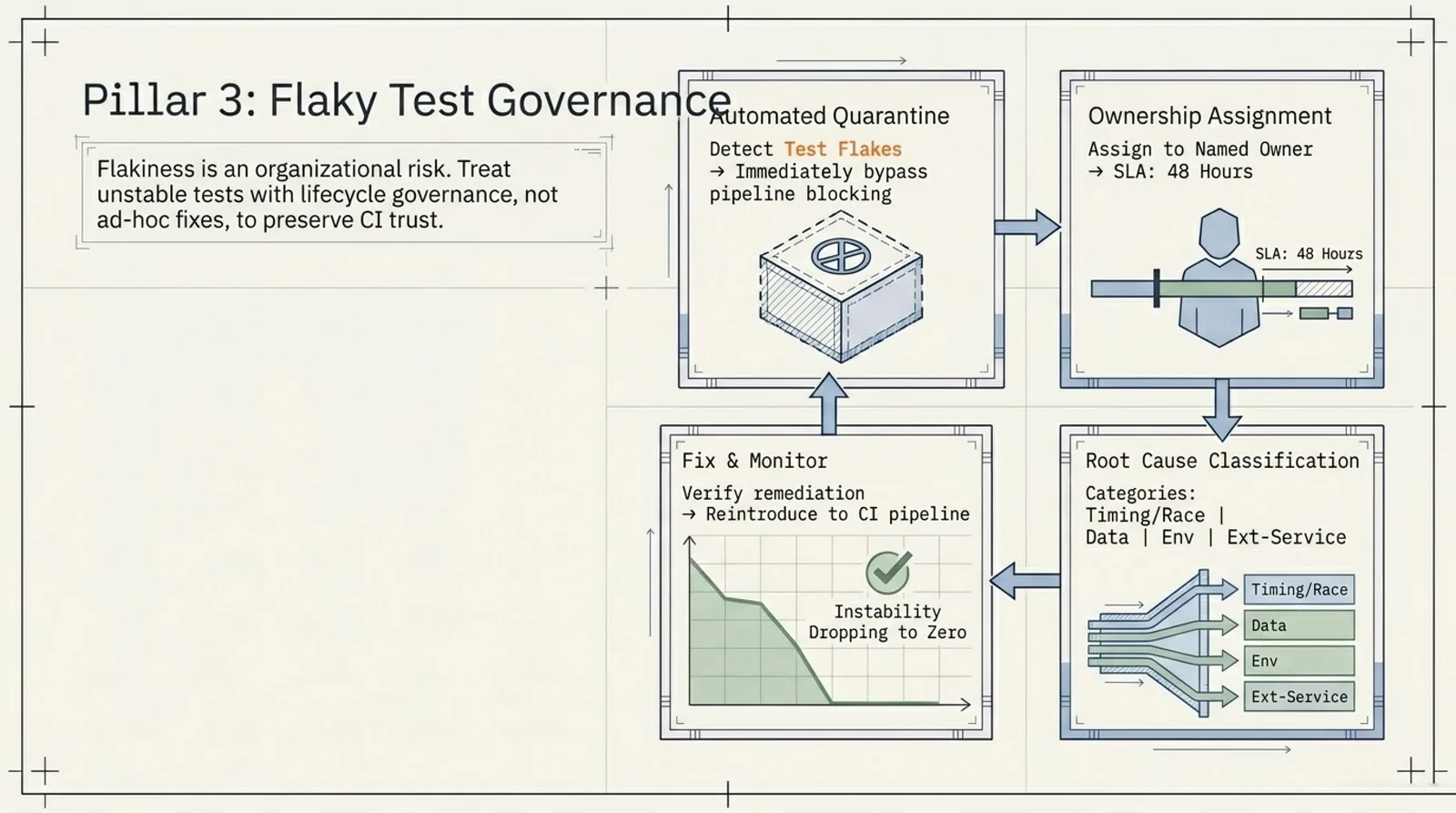
3. Flaky Test Governance
Flaky tests are not just annoying. They corrupt the signal.
If a test fails randomly, teams start ignoring failures. Once that happens, CI is no longer trustworthy. That is a production risk.
A workable governance model includes:
- A named owner for every flaky test.
- A clear classification, such as timing, data dependency, environment instability, or external-service failure.
- Automatic quarantine for unstable tests so they do not block the pipeline.
- Visible metrics for rate, recovery time, and business impact.
I keep a strict ceiling on flaky-test rate and review unresolved items on a fixed cadence. The important thing is not just finding flaky tests. It is making sure they do not linger.
KPI: flaky-test rate, MTTR, percent of flaky tests with an owner and SLA.
Real-world outcome: CI remains something the team can trust, instead of something they argue about every morning.
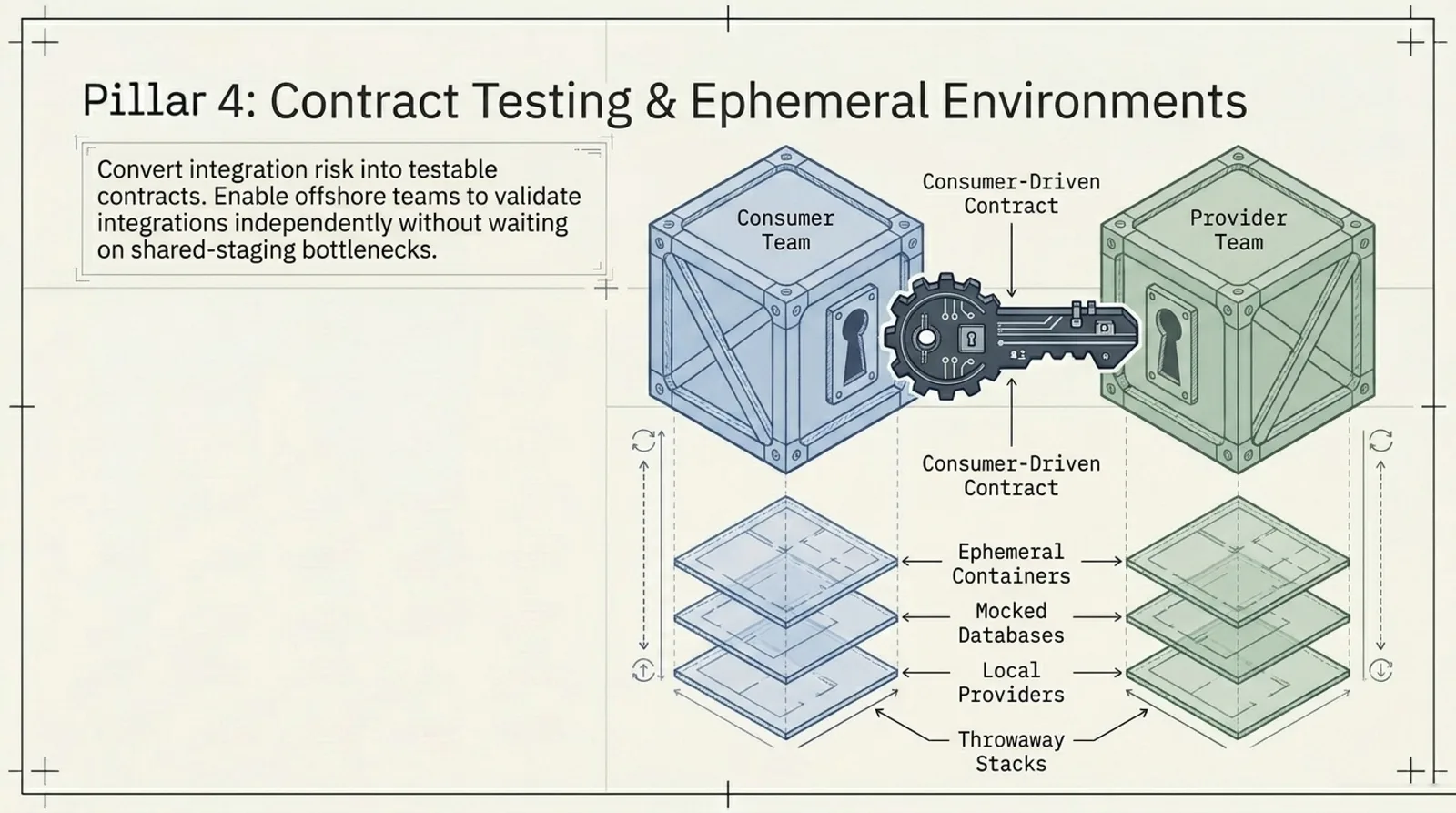
4. Contract Testing and Ephemeral Environments
Distributed teams lose a lot of time on integration bugs that should have been caught earlier.
The problem is usually not the code itself. It is the dependency between teams. One service changes, another breaks, and the failure shows up late in staging or, worse, after release.
Contract testing helps turn those dependencies into explicit checks. Ephemeral environments help make integration closer to reality without depending on shared staging.
In practice, that means:
- Publishing and verifying contracts in CI.
- Blocking merges when provider compatibility fails.
- Spinning up temporary environments per PR for critical integration paths.
- Using disposable dependencies for databases, queues, and brokers.
KPI: integration failures caught before staging, percentage of integrations covered by contracts, environment spin-up time.
Real-world outcome: teams rely less on a shared staging bottleneck and more on tests that actually reflect the service boundary.
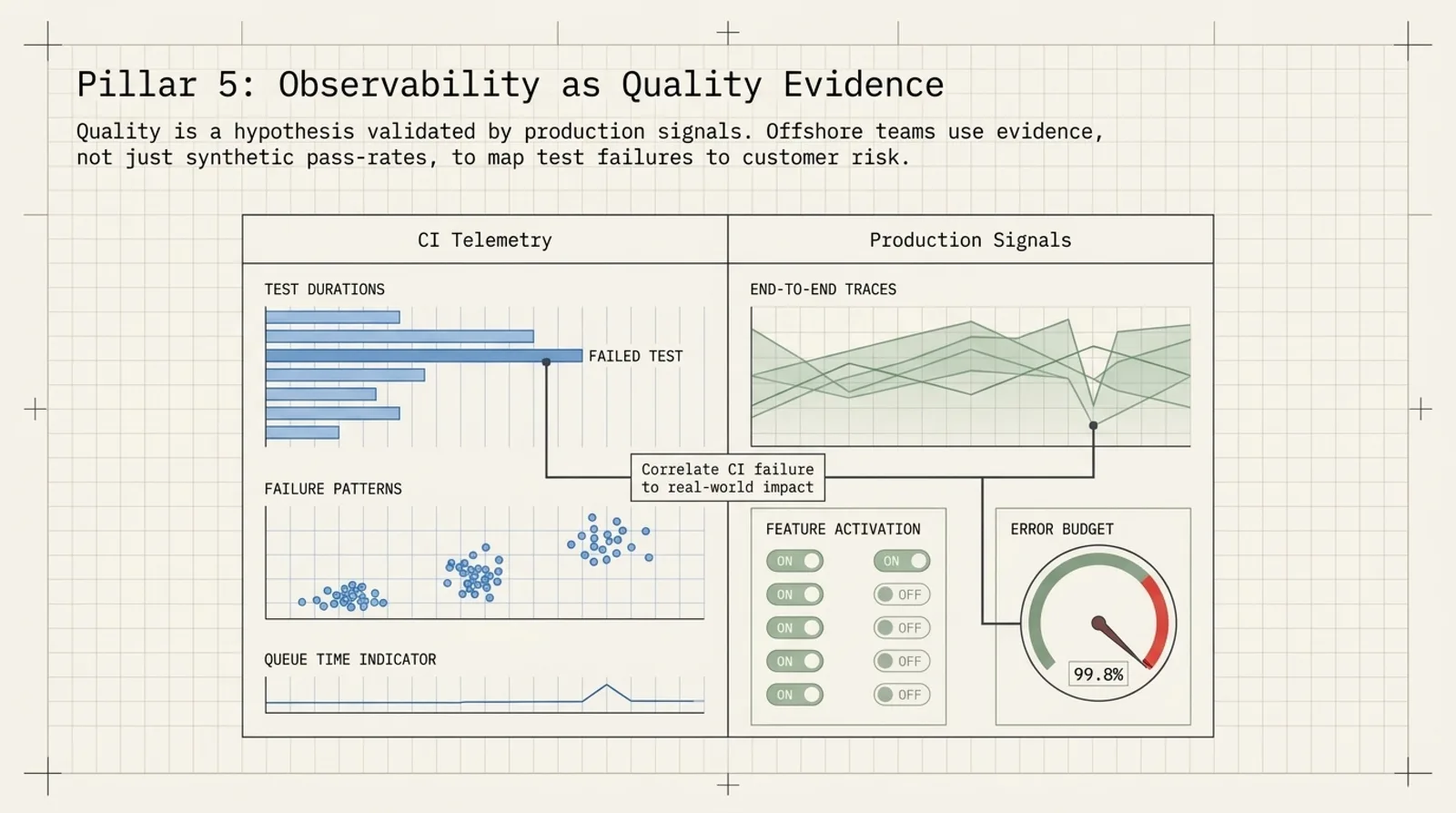
5. Observability as Quality Evidence
Passing tests do not prove the release is safe. They only prove that the specific checks you ran passed.
The stronger signal is production evidence. That means traces, logs, metrics, and customer-impact data that can be tied back to the change.
I look at four sources:
- CI telemetry.
- Traces and spans from services.
- Metrics and logs from production.
- Customer signals such as support tickets, error budgets, and feature-flag behavior.
When possible, I tag test runs with trace IDs and correlate them with production traces. That makes it easier to answer the real question: did this change behave the way we expected?
Feature flags help here too. They let teams control exposure instead of pretending release is a binary event.
KPI: correlation between test failures and production signals, escape rate, rollback rate, hotfix rate.
Real-world outcome: release decisions are based on evidence, not just on a green test dashboard.
The QA Leader's Job
The QA leader should not be the person manually approving every release.
The job is to build the system that makes release decisions repeatable:
- Define ownership for tests, contracts, and flaky items.
- Set thresholds for what blocks a release.
- Decide how signals are escalated when quality drops.
- Make the evidence visible enough that the team can trust it.
That is a much better use of the role. It shifts the job from gatekeeping to system design.
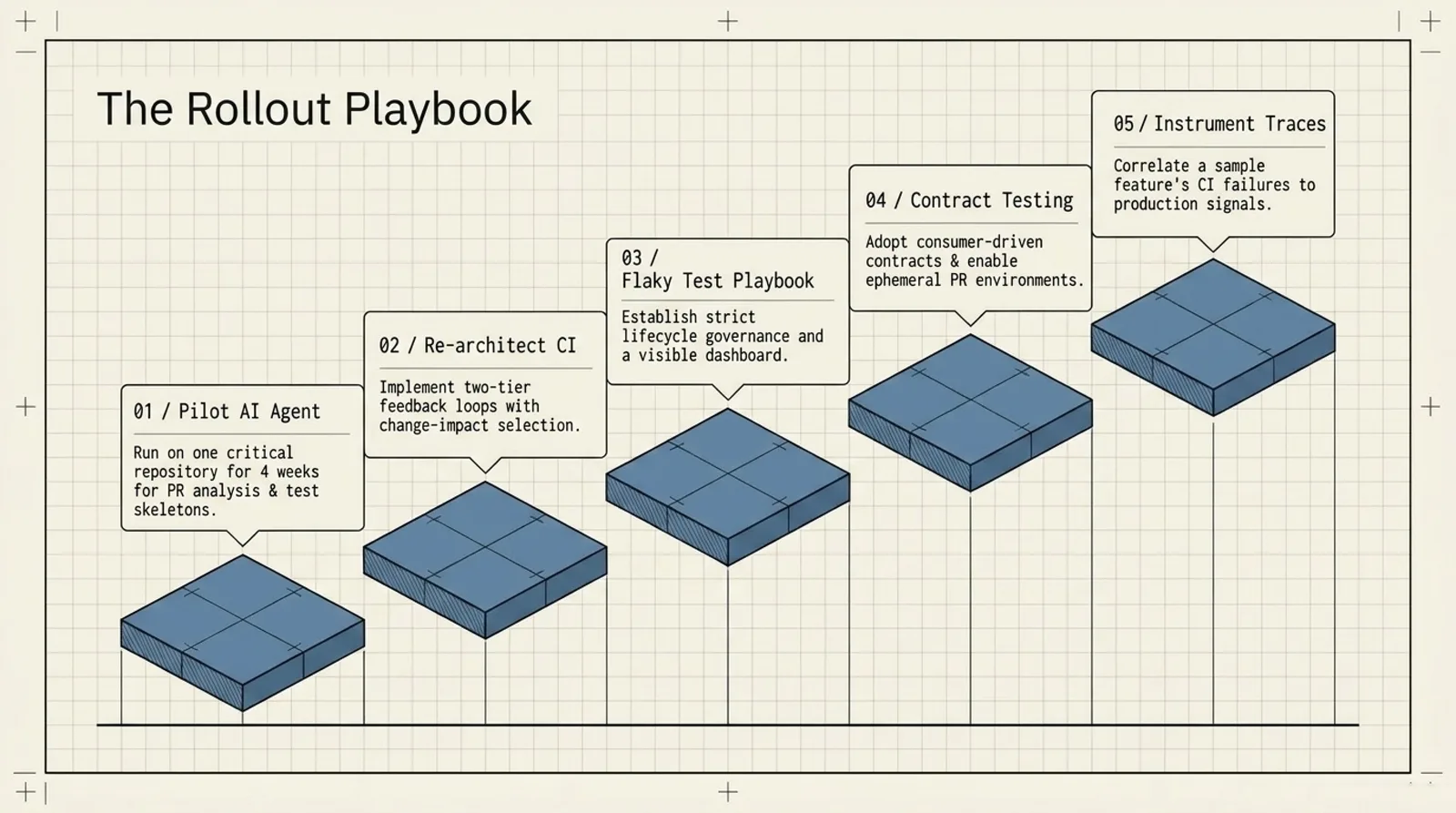
How to Roll It Out
This kind of model should not be introduced all at once. Start where the pain is highest.
- Pick one critical repo and pilot PR risk summaries for four weeks.
- Split CI into fast feedback and deeper validation.
- Build a flaky-test dashboard and quarantine process.
- Add contract tests to two services that break each other often.
- Correlate one real feature rollout with traces, logs, and production metrics.
If the system works, the benefits will show up quickly: fewer false alarms, faster feedback, and less dependence on manual coordination.
Final Word
Offshore QA in 2026 is not about controlling remote testers. It is about building a quality system that works across time zones.
The teams that do this well use AI to reduce noise, CI to focus testing, contract checks to manage dependencies, observability to prove impact, and governance to keep the whole system stable.
That is what a real Quality Operating System looks like in practice.
